(ডিসেম্বর , ৪, ২০১৪, বৃহস্পতিবার)
ডেকরেটর ডিসাইন প্যাটার্ন:
জাভার উপর যশুয়া ব্লক’র লেখা খুবই জনপ্রিয় একটা বইয়ের নাম: ইফেক্টিভ জাভা। জাভার প্রতিষ্ঠাতা জেমস গসলিং নিজেও বইয়ের প্রশংসা করে বলেছেন যে অনেকেই মনে করে তাঁর কোনো জাভার বইয়ের দরকার নেই, কিন্তু তাঁর এই বইটির দরকার এবং খুব ভালো হত যদি তিনি আরো ১০ বছর আগে বইটি পেতেন!! [১]
ইফেক্টিভ জাভা বইটির বর্তমান মুদ্রণে ৭০ টি’র বেশি ‘আইটেম’ আছে। প্রতি আইটেম ২-৩ পৃষ্ঠা করে লেখা। আর কী ভাবে আরো ভালো জাভা কোড লেখা যায়, এক একটি আইটেমে তাই-ই লেখা আছে।
একটা আইটেমর ভাষ্য : জাভা কোড লেখার সময় ‘ইনহেরিটেন্স’ বাদ দিয়ে পারলে ‘কম্পসিশন’ ব্যবহার করা উচিত। কেন তা উদাহরণসহ খুব সুন্দর করে ব্যাখ্যা করা আছে। মজার ব্যাপার হলো, কম্পসিশন ব্যবহার করার উপায় যেটা বলা আছে সেটা আর কিছুই না: ডেকরেটর ডিসাইন প্যাটার্ন!
এই লেখায় প্রথমে ‘ইনহেরিটেন্স’ আর ‘কম্পসিশন’ কি তা সামান্য একটু আলাপ করেই আইটেমের কথায় আসব আর সমস্যার সমাধানে ডেকোরেটর ডিসাইন প্যাটার্ন কিভাবে কাজে আসে, সেইটা দেখে নিব - এক ঢিলে দুই পাখি মারা আর কি!
‘ইনহেরিটেন্স’ হলো ‘extend’ কী-ওয়ার্ড ব্যবহার করে যখন একটা ক্লাস( বা ইন্টারফেস) আরেকটা ক্লাস (বা ইন্টারফেস’র) সব প্রপার্টি, মেথড নিজের মধ্যে নিয়ে আসে। আর ‘কম্পসিশন’ হলো যখন এক ক্লাস আরেক ক্লাস’র রেফারেন্স নিজের মধ্যে ভ্যারিয়েবল হিসাবে রাখে। নিচে একটা উদাহরন দিলাম:
ইনহেরিটেন্স
|
কম্পসিশন
|
public class B extends A {
// …
}
|
public class B {
A obj;
}
|
প্রথেমে একটা উদাহরণ দিয়ে ইনহেরিটেন্স ব্যবহারের অসুবিধা বা সমস্যা কী হতে পারে দেখে নেই [২]
ধরা যাক, আমরা ‘HashSet’ ক্লাস ব্যবহার করব। এই ক্লাসে ‘size ()’ নামে একটা মেথড আছে যা HashSet-এ কয়টা এলিমেন্ট আছে তা বলে দেয়। HashSet -এর বৈশিষ্টই হচ্ছে unique এলিমেন্ট রাখা। অর্থাথ, কেউ যদি একই এলিমেন্ট দুই বা তার চেয়ে বেশি বার রাখতে চায় তবে তা কেবল একটাই রাখবে। ধরা যাক, আমরা জানতে চাই আমাদের HashSe-এ শুরু থেকে এখন পর্যন্ত কয়টা এলিমেন্ট রাখার চেষ্টা করা হয়েছে (খেয়াল করুন কয়টা রাখা আছে তা কিন্তু না।)। এরজন্য আমরা কী করতে পারি?
সহজ উত্তর হচ্ছে আমাদের নিজেদের একটা ক্লাস তৈরী করব যা কিনা HashSet কে ইনহেরিট করবে আর সেই ক্লাস-এ একটা ভ্যারিয়েবল ‘count’ রেখে দিব। আর HashSet-এর ‘add’ বা ‘addAll’ মেথড গুলো ওভাররাইড করব যাতে যখনি কেউ add করতে চাইবে তখন আমরা ‘count’ বাড়িয়ে নিব। আর একটা পাবলিক মেথড ‘getCount’ লিখব যার কাজ হবে ‘count’ রিটার্ন করা। ব্যস, হয়ে যাওয়ার কথা !!
কোডের চেহারা অনেকটা নিচের মত হবে:
import java.util.HashSet;
public class CountingHashSet<E> extends HashSet<E> {
private int count = 0;
@Override public boolean add(E e) {
count += 1;
return super.add(e);
}
@Override public boolean addAll(Collection<? extends E> c) {
count += c.size();
return super.addAll(c);
}
public int getCount() { return count;}
// constructors, ...
}
UML ডায়াগ্রাম আঁকলে তা হবে এই রকম:
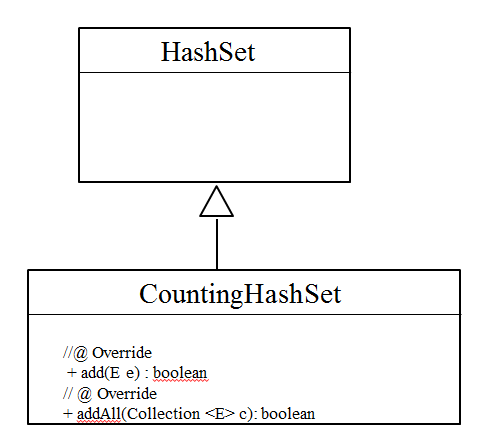
বেশ সোজা কোড। কোনো কিছু add করার আগে আমরা শুধু ‘count’ বাড়িয়ে নিচ্ছি।আর আসল add এর কাজ HashSet-ই তো করছে। আপাত ভাবে মনে হচ্ছে সব ঠিকই আছে, কোথাও কোনো ঝামেলা হবার কথা না। কিন্তু আসলে অনেক গুলো ঝামেলা হবে।
আর তার মূল কারণ হচ্ছে HashSet ক্লাস-এর addAll মেথড।
HashSet-এর addAll মেথড আসলে add মেথড বার বার কল করেই সবগুলো এলিমেন্ট add করে। তাই, যখন আমাদের CountingHashSet ক্লাস-এর addAll মেথড কল হয়, আমরা প্রথমে count বাড়িয়ে নেই, তারপর যখন সুপারক্লাস-এর ‘addAll’ কল করি তখন তা আবার ‘add’ মেথড কল করে। তাতেও সমসস্যা ছিল না, কিন্তু ‘dynamic dispatch’ হয়ে সেই কল আসলে আমাদের CountingHashSet -এর ‘add ‘ মেথডের কাছে চলে আসে, ফলে আমরা count আরেকবার বাড়িয়ে নেই। শেষমেষ, আমরা count দিগুণ বার বাড়াই!
HashSet -এর addAll মেথড যে এইকাজ করে তা তো আমাদের জানার কথা না!! আর ডকুমেন্টেশনও কিন্তু এই ইমপ্লিমেন্টেশন -এর কথা বলে না। কাজেই আমাদের দোষ দিয়ে তো লাভ নেই।
এখন এই সমস্যা সমাধানের কী উপায়?
যেহেতু আমরা এখন ইমপ্লিমেন্টেশন ব্যাপারটা জেনেই ফেললাম, কাজেই আমরা আমাদের CountingHashSet থেকে addAll মেথড বাদ দিয়ে দিলেই কিন্তু ঝামেলা মিটে যায়! আমাদের ক্লাস-এর বাপ HashSet-ই না হয় addAll করলো।
কিন্তু তাতেও ঝামেলা পুরোপুরি শেষ হয় না। ভবিষ্যতে যদি HashSet তার addAll মেথডের ইমপ্লিমেন্টেশন বদলিয়ে ফেলে তাহলে কিন্তু আবার আমরা count কম গুনব - ঠিক না?
আরো ঝামেলা আছে। কী হবে যদি ভবিষ্যতে HashSet আবার addAtFront টাইপ কোনো মেথড নিজের ক্লাস-এ যোগ করে বসে। তখন আমাদেরও কিন্তু তা ওভাররাইড করতে হবে।
আরো একটা ঝামেলা আছে। ধরা যাক, আমাদের CountingHashSet ক্লাস-এ আমরা অন্য কিছু মেথড লিখলাম যা এখনকার HashSet ক্লাস-এ নাই। কিন্তু ভবিষ্যতে যদি HashSet ক্লাস সেই একই নামের অন্য রিটার্ন টাইপ-এর মেথড যোগ করে বসে, তাহলে আমাদের কোড কম্পাইল করবে না !!
মোটকথা হচ্ছে, আমাদেরকে সবসময়ই HashSet -এর উপর নজর রাখতে হবে। কখন কী যে বদলে যায়, সেই ভয়ে থাকতে হবে। এইটা কোড মেইনটেনেন্স বা ব্যবস্থাপনার দুঃস্বপ্ন!
আসল সমাধান টা কী তাহলে?
উত্তরটা হচ্ছে কম্পসিশন ব্যবহার করা। যেহেতু আমরা HashSet -এ একটা নতুন ফীচার/বৈশিষ্ট যোগ করতে চাচ্ছি, সুতরাং HashSet কে কোনভাবে ডেকরেট বা অলংকরণ করতে হবে। আর যেহেতু ইনহেরিট করলে অনেক ঝামেলা, তাই HashSet আর আমাদের CountingHashSet কে আলাদা করতে হবে। একই ইনহেরিটেন্স ট্রি -এর ভেতর রাখা যাবে না। আগে সমাধানের UML ডায়াগ্রাম তা দেখে নেই:
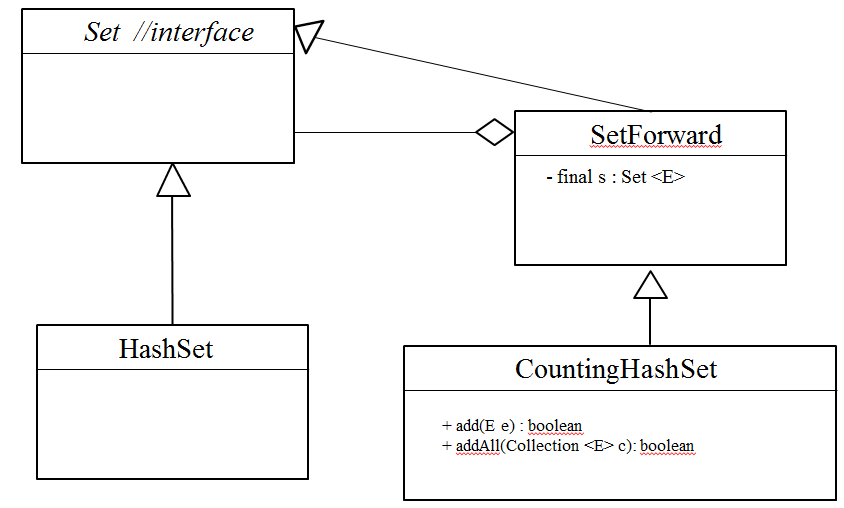
UML ডায়াগ্রামে ডায়মন্ড চিহ্ন দিয়ে কম্পসিশন, আর ত্রিভুজ চিহ্ন দিয়ে ইনহেরিটেন্স বোঝায়। প্রথমেই খেয়াল করুন যে HashSet আর আমাদের CountingHashSet এখন আর সরাসরি ইনহেরিটেন্স (বাপ -ছেলে ) সম্পর্কে নাই।
আমরা আরেকটা ক্লাস, SetForward যোগ করেছি যা কিনা HashSet যেই ইন্টারফেস (Set ) ইমপ্লেমেন্ট করে, সেও একই ইন্টারফেস ইমপ্লেমেন্ট করে। SetForward একটা প্রাইভেট রেফারেন্স ভ্যারিয়েবল s রাখে যার টাইপও Set . আর এই প্রাইভেট রেফারেন্স ভ্যারিয়েবল ব্যবহার করাই কম্পসিশন !
আমাদের CountingHashSet ক্লাস SetForward কে extend করে। আর আমাদের add অথবা addAll মেথড, তাদের কাজ করার (অর্থাথ count বাড়ানোর) আগে বা পরে s ব্যাবহার করে অন্য ক্লাস-এর add বা addAll মেথড কল করবে। এক্ষেত্রে তা HashSet -এর মেথড কল করবে। আর যেহেতু CountingHashSet এখন আর HashSet কে ইনহেরিট করে না, তাই ‘dynamic dispatch ‘ হয়ে কোনো মেথড কল আর (CountingHashSet -এ ) ফিরে আসবে না।
এবার কোড টা দেখি, আশা করি তাহলে ব্যপারটা পুরোপুরি বোঝা যাবে:
public class SetForward<E> implements Set<E> {
private final Set<E> s; // will refer to HashSet, re-usable for any Set
public SetForward(Set<E> s) { this.s = s; } // Constructor that sets private field
public boolean addAll(Collection<? extends E> c) { return s.addAll(c); }
public boolean add( E c) { return s.add(c); }
// … more methods
}
public class CountingHashSet<E> extends SetForward<E> {
private int addCount = 0; // does the actual counting
public CountingHashSet(Set<E> s) { super(s); }
public boolean addAll(Collection<? extends E> c) {
s.addAll(c);
count += c.size();
}
public boolean add(E c) { s.add(c); count++; }
// … more methods
}
আর সব শেষে আমাদের যা করতে হবে তা হচ্ছে, (main মেথডে) HashSet -এর একটা অবজেক্ট তৈরী করে আমাদের CountingHashSet - ক্লাস-এ পারামিটার হিসাবে পাস করতে হবে। অনেকটা এইভাবে:
Set hashSetObj = new HashSet();
CountingHashSet ourObj = new CountingHashSet(hashSetObj);
(যেহেতু আমাদের SetForward ক্লাস আর HashSet ক্লাস দুইজনই Set ইমপ্লেমেন্ট করে, আবার আমাদের CountingHashSet ক্লাস SetForward -কে extend করে, তাই আমাদের CountingHashSet তার Constructor -এ HashSet অবজেক্ট নিতে পারবে)
ব্যস, সব সমস্যার সমাধান হয়ে গেল। এখন HashSet অবজেক্ট ভবিষ্যতে যতই পরিবর্তিত হোক, আমাদের কোড-এ আর ঝামেলা হবে না।
আর এই যে আমরা HashSet কে ডেকরেট বা অলঙ্করণ করলাম, এইটাই ডেকরেট ডিসাইন প্যাটার্ন। যেকোনো অবজেক্ট কে কম্পসিশন ব্যবহার করে (Runtime -এ) অলঙ্করণ করাই এর মূল ভাষ্য।
মজার ব্যাপার হচ্ছে, আমরা অনেকই হয়ত এরই মধ্যে না জেনেই ডেকরেট ডিসাইন প্যাটার্ন ব্যবহার করেছি। java.io প্যাকেজে অনেক ক্লাস ডেকরেট ডিসাইন প্যাটার্ন ব্যবহার করে [৩]। কোনো টেক্সট ফাইল পড়ার সময় আমরা না জেনেই ওই ক্লাস গুলো ব্যবহার করি। যেমন:
FileReader fr = new FileReader(“input.txt”);
BufferedReader txtReader = new BufferedReader(fr);
এখানে কিন্তু FileReader অবজেক্ট fr কে BufferedReader ডেকরেট করছে! কিছুই না, BufferedReader শুধুমাত্র বাফারিং বৈশিষ্ট FileReader -এ যোগ করছে।
ডেকরেট সহ অন্যান্য ডিসাইন প্যাটার্ন আরো ভালো ভাবে বোঝার জন্য দুর্দান্ত একটা বই হচ্ছে হেড ফার্স্ট ডিসাইন প্যাটার্ন। আরো সহজ করে অনেক ছবি দিয়ে কমিক স্টাইল -এ প্রতিটা ডিসাইন প্যাটার্ন বইটাতে বোঝানো হয়েছে।
সবশেষে কিছু ক্রেডিট দিয়ে দেই:



Thanks Ishtiaque! It's a good writing!
ReplyDelete